Learn the platform through workflows, not product names.
New users usually do better when they start with one goal: establish health, investigate an incident, tune an application, or connect observability to the rest of the estate.
Use this launchpad to choose the right OCI service, understand how the platform fits together, and move from overview to hands-on guidance across Monitoring, Log Analytics, APM, Database Management, enterprise applications, and integrations.
A guided landing page for operators, developers, DBAs, security teams, and decision makers using OCI Observability.
The platform already has the depth. This homepage changes the starting point: begin with a role, follow a troubleshooting workflow, or use the command palette when you know exactly where you want to go.
Pick who you are and where you work — we'll highlight the levels, services, and the lens to start from. Access to every view is governed by OCI IAM: each persona maps to an OCI Group with policies scoped to the right compartments.
Each level builds on the last. Jump straight to the launchpad module that delivers it, or open the full ladder in the guide.
Same eight personas as the guide — what each one looks for, and the OCI services they live in.
Your step-by-step path to complete cloud-native observability, from business value to code
Establish a centralized, auditable record of all cloud and on-premise actions. Ingest, parse, and retain log streams to satisfy global compliance standards (ISO 42001, SOC2, GDPR) while laying the foundation for threat hunting.
Consolidating disparate logs into OCI Log Analytics removes blind spots, reduces compliance liabilities, and eliminates the cost of managing scattered log storage servers.
Create dedicated OCI Compartments and write IAM policies granting the Management Agent permission to upload telemetry.
Deploy the OCI Management Agent across your VM fleets and bare-metal nodes to collect system logs and OS metrics.
Register Log Groups, configure log collection paths, and apply built-in or custom parsers (JSON, Syslog, WebLogic).
Define automated Object Storage archival rules to transition older logs from hot query pools to cost-effective cold tiers.
Use industry-standard open source collectors like Fluentd to securely forward application log files to OCI Log Analytics endpoints.
<source>
@type tail
path /var/log/app/app.log
pos_file /var/log/td-agent/app.log.pos
tag oci.loganalytics.portal
<parse>
@type json
time_key timestamp
time_format %Y-%m-%dT%H:%M:%S.%L%z
</parse>
</source>
<match oci.loganalytics.**>
@type oci_log_analytics
namespace <TENANCY_NAMESPACE>
log_group_id ocid1.loggroup.oc1.eu-frankfurt-1.aaaaaaaaxf...
log_source_name OCI_APM_Trace
co_id ocid1.compartment.oc1..aaaaaaaasx...
region eu-frankfurt-1
auth_type instance_principal
</match>Establish metric baselines and automated alert gates. Move from a reactive fire-fighting posture to proactive, anomaly-driven operations, protecting system availability before outages reach end users.
Centralized alerting connects OCI metrics to on-call schedules, minimizing disruption and driving strict accountability via automated SLA/SLO reporting.
Align platform SLIs (latency, error rate) with business outcomes. Establish acceptable SLO budgets (e.g. 99.9% uptime).
Publish custom application and system metrics to the secure OCI Monitoring service namespace.
Create OCI Monitoring alarms and bind them to OCI Notification topics representing on-call responder groups.
Configure Service Connector Hub to route critical alarms directly to PagerDuty or Slack webhooks.
Configure OCI Monitoring alarms using Metric Query Language (MQL), or pull metrics directly into an open-source Prometheus/Grafana stack using OCI Management Agent endpoint exporters.
# Trigger alert if the HTTP error rate exceeds 5% for three consecutive 1-minute intervals
HttpRequests[1m]{resourceId = "ocid1.instance.oc1..."}.status_code != "200"
| stats count() as ErrorCount
| HttpRequests[1m]{resourceId = "ocid1.instance.oc1..."}.stats(count) as TotalCount
| (ErrorCount / TotalCount) * 100 > 5scrape_configs:
- job_name: 'oci-management-agent-metrics'
scrape_interval: 15s
metrics_path: '/metrics'
static_configs:
- targets: ['10.0.2.15:9100'] # IP of the node running OCI Management Agent exporter
metric_relabel_configs:
- source_labels: [__name__]
regex: 'oci_computeagent_(.*)'
target_label: __name__Pinpoint distributed latency bottlenecks and transaction-level query blocks. By tracing requests across microservices and cloud databases, you prevent slow page response rates from driving away active users.
APM Browser RUM tracks actual user transaction latency, while DB Management provides DBA dashboards that replace archaic database maintenance CLI workflows.
OCI Stack Monitoring's capabilities — full-stack discovery, topology, and application-stack health — are being merged into the OCI Monitoring service. Existing investment carries forward; there is no need to replace it with separate services.
Provision OCI APM domains and retrieve your Public Datakeys (for browser RUM) and Private Datakeys (for server agents).
Inject the APM Browser RUM JS agent into main templates to record end-user page speed and AJAX performance.
Deploy OpenTelemetry backend instrumentation across your microservices to stream tracing spans to the APM collector.
Register Autonomous, Cloud, and External DBs into OCI Database Management for Performance Hub and AWR metrics.
Propagate tracing context across microservices using W3C Trace Context HTTP headers, and capture execution spans for SQL queries.
from opentelemetry import trace
tracer = trace.get_tracer("demo-portal")
def get_treasury_records(db_conn, search_term):
# Start a span to trace this transaction
with tracer.start_as_current_span("treasury.search") as span:
span.set_attribute("db.system", "mssql")
span.set_attribute("db.statement", f"SELECT * FROM treasury WHERE name = '{search_term}'")
# Verify SQL injection attempt (Level 3 security attribute tracking)
if "'" in search_term:
span.set_attribute("security.attack.type", "sqli")
span.set_attribute("security.attack.severity", "critical")
cursor = db_conn.cursor()
cursor.execute("SELECT * FROM treasury WHERE name = %s", (search_term,))
return cursor.fetchall()import httpx
from opentelemetry import trace
from opentelemetry.propagate import inject
def call_inventory_service():
# Inject current span context into W3C traceparent headers
headers = {}
inject(headers)
# headers will contain:
# 'traceparent': '00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01'
response = httpx.get("http://inventory.service/items", headers=headers)
return response.json()Apply machine learning and LLMs to infrastructure diagnostic datasets. Predict database and compute capacity boundaries, cluster raw logs to identify anomalies, and let AI agents summarize complex incidents using natural language.
Centralized AI diagnostic services enable non-expert engineers to query cluster metrics, analyze log patterns, and predict scaling blockages safely via secure Model Context Protocol (MCP) bridges.
Register your databases and host compartments into Operations Insights to begin 30-day capacity trend tracking.
Enable LoganAI machine learning models to cluster recurring log lines and highlight anomalous spikes.
Deploy the Model Context Protocol (MCP) server container, mounting secure OCI API read-only credentials.
Integrate your corporate chat client or development environment with the MCP server to start querying OCI.
Configure an MCP server schema to connect LLMs to OCI APIs, or use OCI Log Analytics Query Language (OCL) with machine learning modifiers like `cluster` to isolate log anomalies.
{
"mcpServers": {
"oci-observability": {
"command": "python",
"args": ["-m", "mcp_server.main"],
"env": {
"OCI_COMPARTMENT_OCID": "ocid1.compartment.oc1..aaaaaa...",
"OCI_AUTH_MODE": "instance_principal",
"OCI_LOG_ANALYTICS_NAMESPACE": "tenancy_namespace"
}
}
}
}# Cluster application logs over the last 24 hours to isolate warning and error anomalies
'Log Source' = 'OCI APM Trace'
| where 'Entity Type' = 'Host'
| cluster
| where 'Cluster Type' = 'Anomaly'
| stats count() as Occurrences by 'Cluster Content'
| sort - OccurrencesThese flows turn the service catalog into a user journey: observe, investigate, explain impact, and automate the next step.
New users usually do better when they start with one goal: establish health, investigate an incident, tune an application, or connect observability to the rest of the estate.
Comprehensive tools for monitoring, analysis, and management
Collect and visualize metrics from OCI resources with customizable dashboards and intelligent alerting.
AI-powered log analysis with ML clustering, anomaly detection, and 300+ pre-built parsers for any log source.
End-to-end visibility from browser to database with distributed tracing and real user monitoring.
Auto-discover and monitor your full application stack. Its capabilities are being merged into the OCI Monitoring service.
Analyze resource utilization, forecast capacity needs, and identify optimization opportunities across your fleet.
Comprehensive fleet management with Performance Hub, SQL tuning advisors, and proactive problem detection.
Free tier vs. paid capabilities at a glance
Begin your observability journey in minutes
Navigate to the OCI Console and enable the Observability services you need. Most services are available in all OCI regions and can be enabled in minutes with just a few clicks.
Install the unified Management Agent on your compute instances to collect metrics, logs, and traces. The agent supports Linux, Windows, and Solaris operating systems.
Set up log sources, enable service connectors, and configure APM instrumentation for your applications. Use pre-built integrations or create custom configurations.
Create custom dashboards to visualize your data and set up alarms to get notified when something needs attention. Use saved searches and scheduled reports for ongoing monitoring.
Validate your expertise with the official Oracle certification (1Z0-1111-25)
Site Reliability Engineers, Cloud Operations, Application Developers, Cloud Administrators, and roles involved in monitoring and troubleshooting OCI environments.
Exam objectives mapped to core competency areas
Summarize OCI Observability and Management Services portfolio and understand how they work together.
Demonstrate OCI Monitoring service with metrics and alarms. Configure alarm definitions using best practices.
Analyze OCI Events Service concepts. Determine event structure, types, rules, and integration with OCI services.
Distinguish log categories and enable log collection. Work with OCI Logging for centralized log management.
Create visualizations and identify log data patterns with OCI Logging Analytics. Use ML clustering and anomaly detection.
Monitor applications with deep visibility into end-user experience using distributed tracing, RUM, and synthetics.
Monitor distributed components of an application stack with full-stack observability and topology views.
Real-world scenarios showcasing how OCI Observability services work together
When a critical alarm fires, use OCI's integrated observability stack to quickly correlate metrics, logs, and traces to identify the root cause and reduce mean time to resolution (MTTR).
Combine Cloud Guard's automated threat detection with Log Analytics' ML-powered anomaly detection to identify and investigate security incidents across your OCI tenancy.
Use APM's distributed tracing combined with Real User Monitoring (RUM) to identify performance bottlenecks across your entire application stack, from frontend to backend to database.
Use Operations Insights to analyze historical resource utilization patterns, forecast future capacity needs, and identify optimization opportunities across your database and compute fleet.
Monitor your OKE (Oracle Container Engine for Kubernetes) clusters with comprehensive observability covering cluster health, pod metrics, application traces, and container logs.
Use Database Management's Performance Hub to analyze ASH, AWR, and real-time SQL monitoring data to identify and resolve database performance issues.
Monitor your Oracle E-Business Suite deployment end-to-end using Stack Monitoring's auto-discovery capabilities combined with Log Analytics for application and database logs.
Leverage observability data from Operations Insights and Monitoring to identify underutilized resources, right-size infrastructure, and optimize your OCI spend.
Real screenshots from OCI Observability services
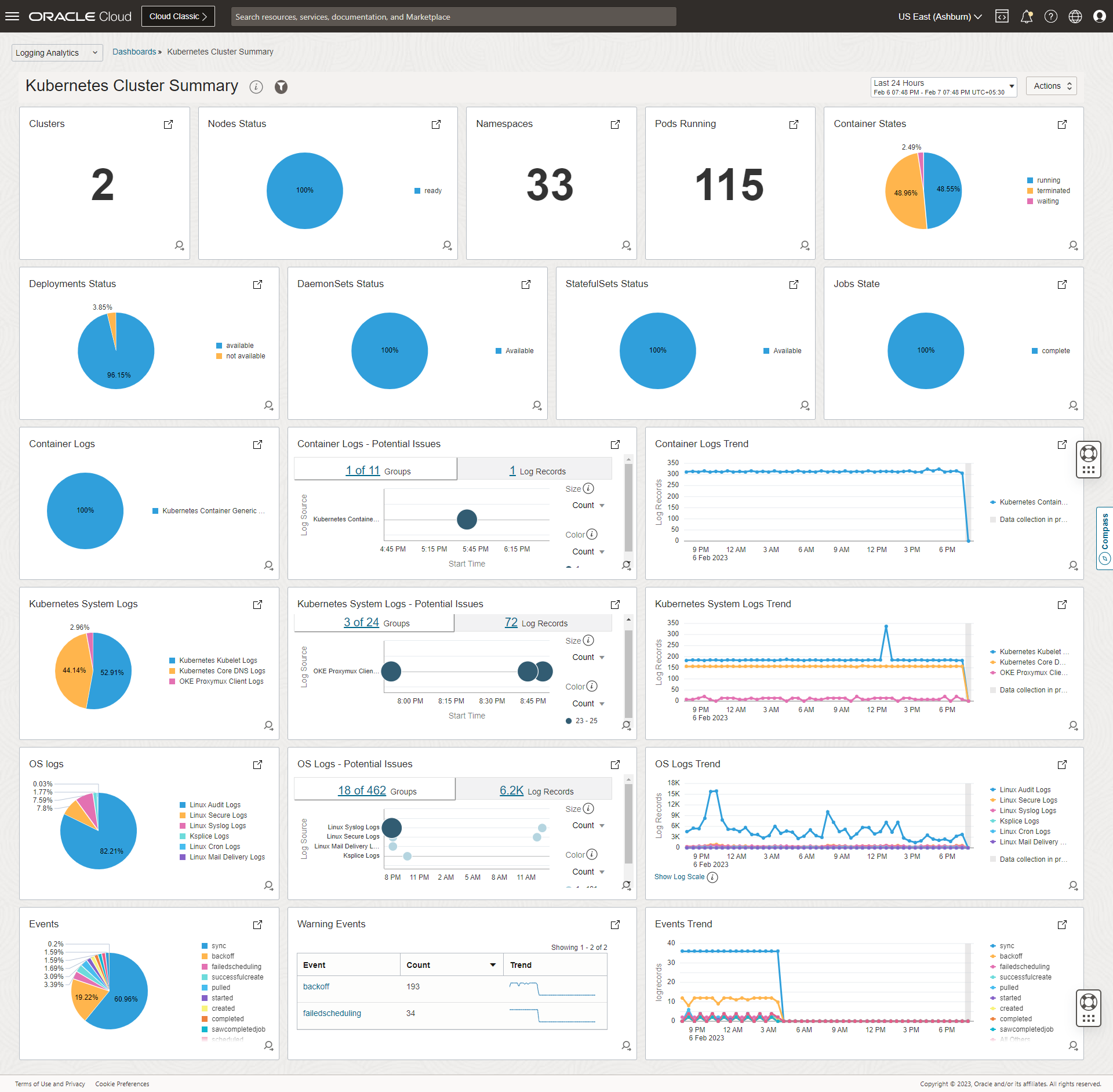
Comprehensive view of cluster health, resource utilization, and workload status in Log Analytics
Log Analytics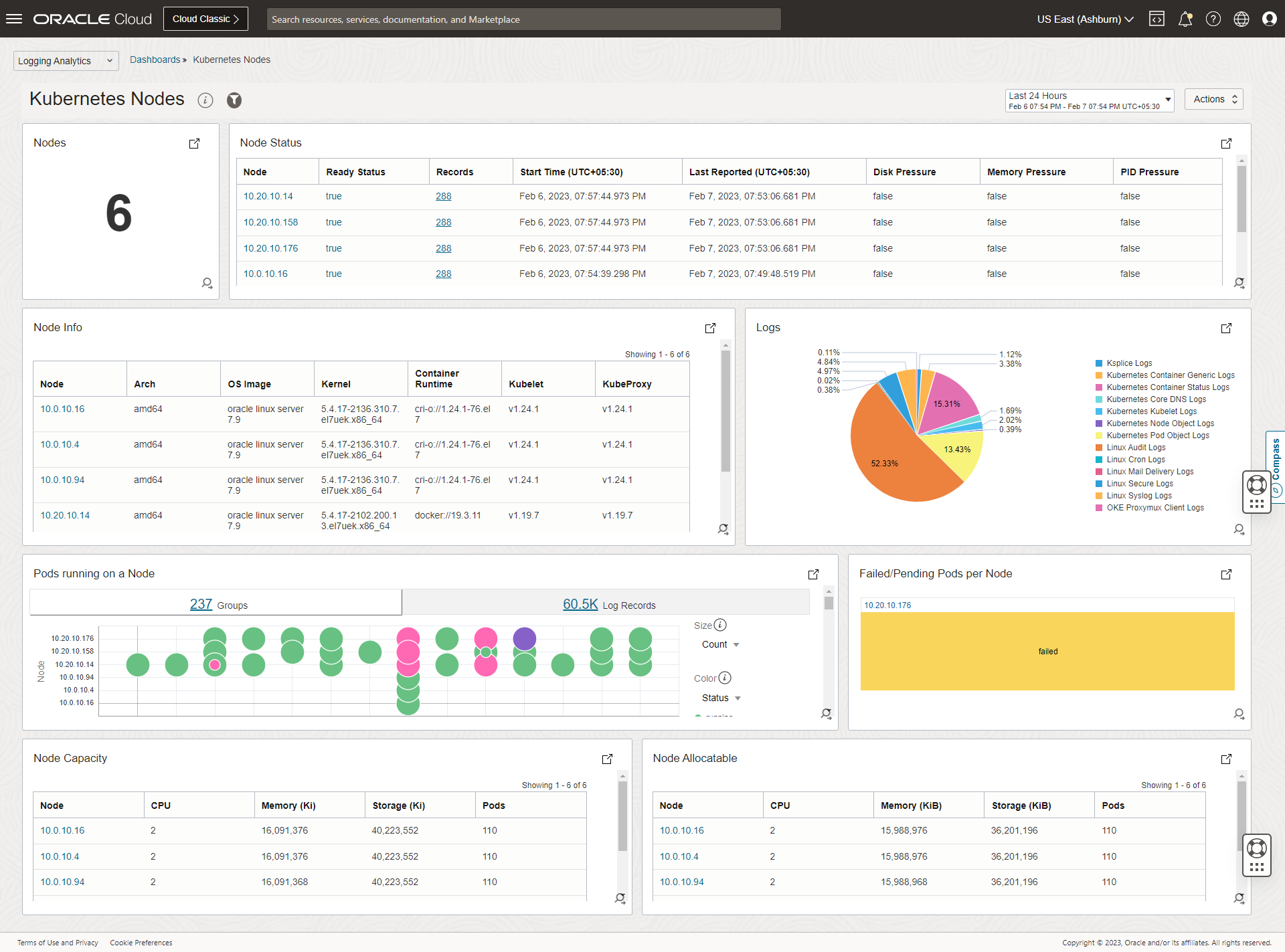
Node-level metrics including CPU, memory, disk usage, and pod distribution across the cluster
Log Analytics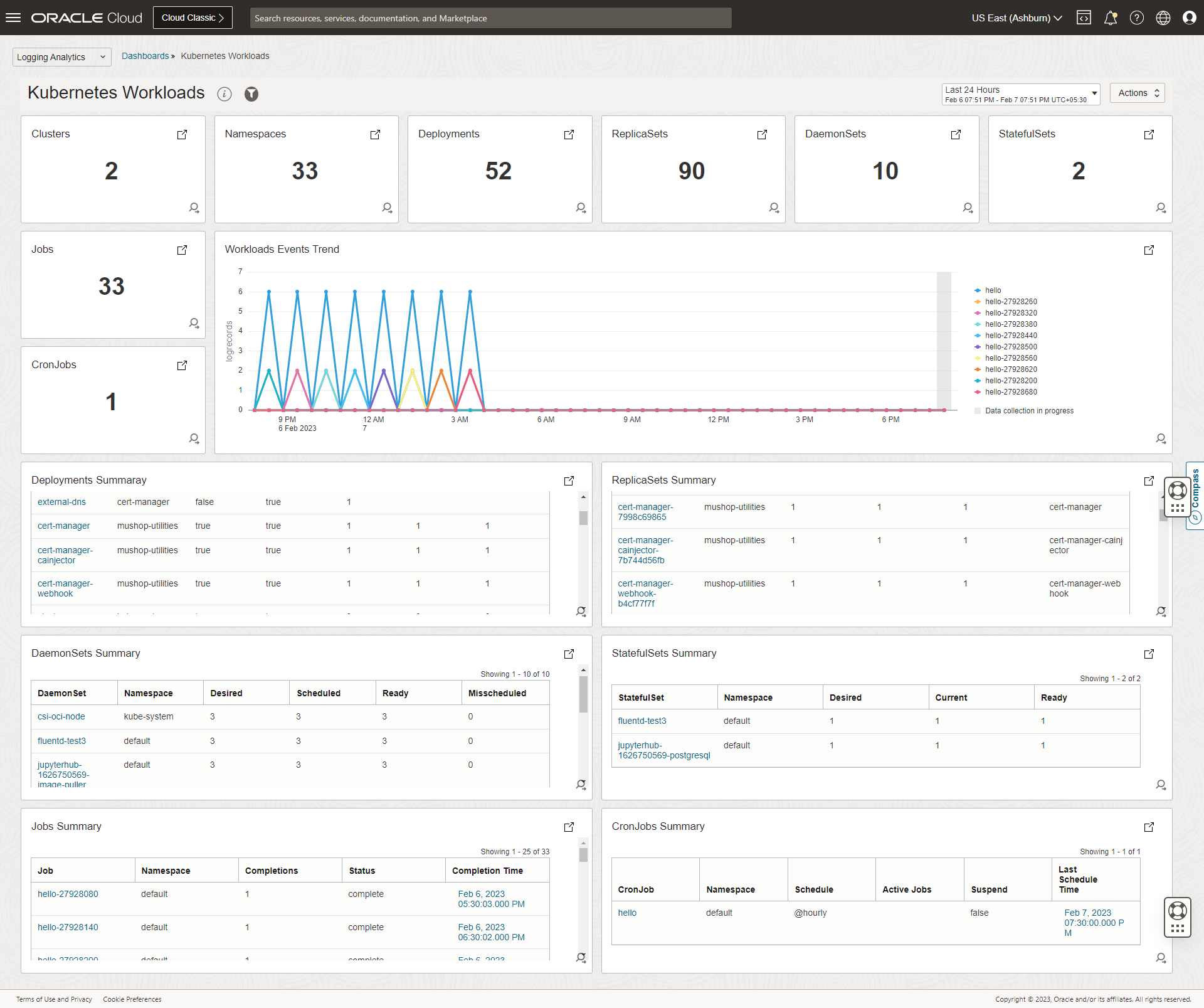
Deployment health, replica status, and container-level insights for all workloads
Log Analytics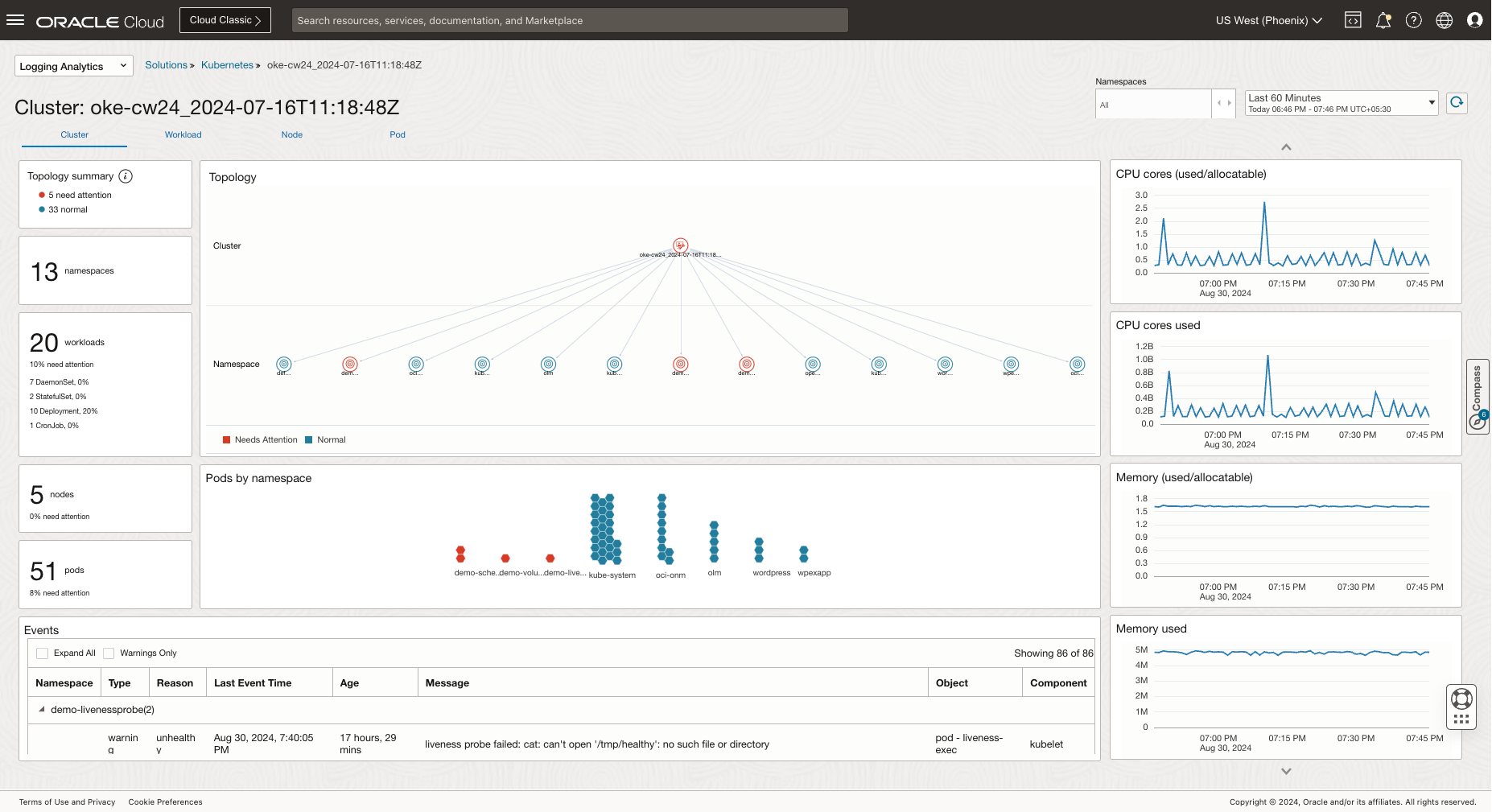
Visual representation of cluster topology with namespaces, workloads, and services
Log AnalyticsSecurity monitoring, threat detection, and compliance solutions
Build a cloud-native Security Operations Center using OCI Log Analytics Security Fundamentals Dashboards. Aggregate and analyze security events across your entire OCI infrastructure with pre-built threat detection rules and compliance reporting.
Monitor OCI Web Application Firewall traffic and security events using Log Analytics. Visualize attack patterns, blocked requests, and protection rule effectiveness with pre-built WAF dashboards.
Gain deep insights into OCI API Gateway traffic patterns, latency metrics, error rates, and usage analytics. Create custom dashboards to monitor API consumers, throttling events, and backend response times.
Comprehensive observability and security solutions for Oracle Databases
Oracle Data Safe provides essential security capabilities for Oracle Databases including security assessments, user assessments, data masking, activity auditing, and sensitive data discovery. Available free for OCI databases or as a paid service for on-premises and non-OCI databases.
Stream Data Safe audit events to Log Analytics for advanced correlation, custom dashboards, and long-term retention. Combine database security events with infrastructure logs for comprehensive security posture analysis.
Achieve comprehensive Oracle Database observability by combining Operations Insights for capacity planning and SQL analytics, Database Management for performance monitoring, and Log Analytics for alert and audit log analysis.
Leverage the Oracle Database MCP (Model Context Protocol) server with Generative AI to enable natural language interactions for database troubleshooting, performance analysis, and automating routine DBA tasks through conversational interfaces.
Leverage OCI Log Analytics as a unified platform for OS security logs, Prometheus metrics ingestion, Data Safe audit events, network flow logs, and Oracle Fusion HCM application logs. Enhanced with LoganAI for intelligent analysis and Logan MCP server for 3rd party LLM integration.
Monitor Oracle Fusion Cloud applications including Visual Builder apps with OCI Application Performance Monitoring. Gain end-to-end visibility into user experience, transaction traces, and backend performance for your Fusion deployments.
Ingest Oracle Fusion Applications logs into OCI Log Analytics — application, audit, and security logs from Fusion ERP, HCM, SCM, and CX — using the BI Cloud Connector (BICC) export plus the Fusion Applications Observability solution. Parse, enrich, and correlate them with the OCI-side signals, then build saved searches and dashboards for functional and security teams.
Monitor Oracle Integration Cloud (OIC) flows, connections, and errors using Log Analytics. Collect integration activity logs, track message flows, and create dashboards for integration health and performance analysis.
Build and execute metrics queries with dynamic namespace and region selection
Add a query and click "Run Query" to visualize metrics
Quick reference for OCI metric namespaces
oci_computeagent - Agent-collected metricsoci_compute_infrastructure_health - Instance healthoci_autonomous_database - ADB metricsoci_database - Base DB metricsoci_mysql_database - MySQL HeatWaveoci_vcn - VCN flow metricsoci_lbaas - Load Balanceroci_service_gateway - Service Gatewayoci_objectstorage - Object Storageoci_blockstore - Block Volumeoci_filestorage - File StorageComplete monitoring for Oracle E-Business Suite on OCI
Auto-discover and monitor the complete EBS stack with pre-built dashboards
Collect and analyze EBS application logs, concurrent manager logs, and database alert logs
End-to-end transaction tracing from browser to database with RUEI integration
Performance Hub, SQL Tuning, and fleet-wide database management
Hands-on experience with EBS Observability using OCI Stack Monitoring and Log Analytics
Launch WorkshopObservability for Oracle Fusion Applications and Integration Cloud
Root Cause Identified: Order #ORD-2024-78432 failed at OIC integration due to malformed JSON payload (missing "shipping_address" field).
ERROR [IntegrationFlow] OrderSync: ValidationException - Required field 'shipping_address' is null for order ORD-2024-78432
[2024-01-31 02:34:17] BIP_REPORT: Waiting for input file...
[2024-01-31 02:34:17] OIC_FTP_ADAPTER: Connection timeout to ftp.partner-bank.com:21
[2024-01-31 02:34:17] OIC_FTP_ADAPTER: Retry 1/3 failed
[2024-01-31 02:34:47] OIC_FTP_ADAPTER: Retry 2/3 failed
[2024-01-31 02:35:17] OIC_FTP_ADAPTER: Retry 3/3 failed - giving up
One place for Prometheus, Fusion, OIC, MCP, LoganAI, and third-party incident workflows.
Use this module when the question is not “which OCI service exists?” but “how do I wire the platform into the rest of the estate?” It brings together ingestion, packaged-app monitoring, AI copilots, and incident-response handoffs.
Telemetry ingestion, enterprise apps, AI copilots, and incident escalation.
Move from metric spike to parser, trace, or responder handoff without hunting across modules.
If the team knows the symptom but not the OCI service, start here and then pivot into the deeper lanes below.
Use Management Agent collection or remote-write pipelines to get Prometheus data into the OCI observability plane, then enrich that data with LoganAI, clustering, and incident correlations.
Bring together Fusion audit/activity data, OIC activity streams, Log Analytics parsers, APM browser/server telemetry, and database insights to debug business flows instead of isolated services.
Expose observability domains through MCP so copilots can query live logs, metrics, AWR, and Cloud Guard context instead of relying on pre-baked answers.
Close the loop by sending OCI Monitoring or Log Analytics signals into the systems teams already use for triage, escalation, and remediation.
Choose the integration shape that matches your operating model.
Prometheus, service logs, Flow Logs, and Data Safe feed a shared Log Analytics tenancy. Monitoring drives alerts. MCP copilots read from curated observability APIs.
Business-process issues start in Fusion or OIC, pivot into parsers, trace evidence, and Database Management, and finish with a handoff to the application team or partner endpoint owner.
Monitoring alarms fan out through Notifications, Slack, or PagerDuty. Incident responders use LoganAI and MCP-backed copilots to summarize impact and trigger automations.
Prioritize the server contracts that give users the highest leverage during investigation and remediation.
Run searches, summarize clusters, and pivot into anomaly investigations.
query_logs
cluster_patterns
summarize_window
Expose AWR, SQL tuning, and performance-hub summaries to copilots.
get_awr_report
analyze_sql
list_wait_events
Normalize packaged-app evidence so business incidents can be explained in plain language.
list_failed_flows
fetch_activity_logs
trace_business_order
Bridge observability signals into notifications, runbooks, and remediation workflows.
create_incident
notify_channel
trigger_function
AI-powered log analysis for any source, any format, any scale
Back-off restarting failed container * in pod *
These CrashLoopBackOff errors correlate with a memory limit increase deployed at 14:15. Consider reverting the change or increasing pod memory limits.
Automatically group similar log patterns without manual regex
Spot unusual patterns and deviations from baseline behavior
Ask questions in plain English, get actionable results
Out-of-the-box support for OCI, Linux, databases, and more
LoganAI enables you to analyze logs using AI for faster investigation and troubleshooting.
Get concise summaries of large log datasets in plain language, dramatically reducing time-to-insight.
AI suggests relevant follow-up queries based on your current investigation context.
Complex log patterns explained in simple terms for faster understanding.
Automatically correlate related events across multiple log sources.
Unsupervised ML automatically categorizes logs into actionable insights
Clusters automatically identified as potential problems requiring attention
One-time events that indicate anomalies in the system
Cluster patterns correlated in time showing emerging issues
Correlate audit logs, VCN flow logs, and application logs to investigate security incidents.
Use ML clustering to identify error patterns across distributed microservices.
Generate compliance reports from centralized log data with scheduled searches.
Analyze application and infrastructure logs to identify performance bottlenecks.
End-to-end visibility from browser click to database query
Users complain checkout is slow, but server CPU is only 20%
Devs can't reproduce errors that users in Brazil are seeing
Uncaught TypeError: Cannot read property 'submit' of undefined at checkout.min.js:847
This client-side error affects 73% of Brazilian users due to a CDN caching issue with the new checkout script.
Enrich your Real User Monitoring data with custom dimensions and metrics for deeper analysis.
Filter and group by user properties, page categories, or custom tags
window.apmrum.udfAttributes = [
{ name: 'userId', value: 'user@example.com' },
{ name: 'pageCategory', value: 'checkout' }
];
Aggregate and alert on custom numeric values like cart totals or item counts
window.apmrum.udfAttributes = [
{ name: 'cartTotal', value: 149.99 },
{ name: 'itemCount', value: 3 }
];
Execute functions on each span to capture real-time state
window.apmrum.udfAttributes = [
{ name: 'cartItems', value: () => getCartCount() }
];
Root Cause: The slowness is caused by the 3rd party payment provider, not your code. The Payment Gateway service is taking 3 seconds to respond.
Proactively detect availability and performance issues before end users experience them using 8 different monitor types.
Monitor specific URLs and page load times
Record and replay user journeys with multi-step transactions
Test REST endpoints with custom headers and payloads
Monitor server/host availability via ping and port checks
DNS Server, DNS Trace, and DNSSEC validation
Measure SQL query performance against Oracle databases
Measure FTP operation performance and latency
Multi-step API transaction workflows
Scripted browser runs login test every 5 minutes from global vantage points. Failures trigger immediate alerts.
SELECT * FROM payment_tokens WHERE user_id = ? AND status = 'ACTIVE' ORDER BY created_at DESC LIMIT 1
Execution: 2847ms
Collect traces and metrics from multiple sources including language agents, open standards, and APIs.
Drill down from slow page loads to the exact database query or API call causing issues.
Identify regional performance disparities with RUM and optimize CDN configuration.
Detect outages before users report them with synthetic monitors running 24/7.
Compare performance metrics before and after deployments to catch regressions.
Trace requests across dozens of services with distributed tracing and service maps.
Track response times and error rates against SLA commitments with custom dashboards.
Gain deep visibility into your database and host fleet performance. Operations Insights provides capacity planning, resource utilization analysis, and SQL analytics to help you optimize costs and ensure performance.
Capacity planning and resource analytics for databases and hosts
Forecast CPU, memory, and storage needs up to 30 days ahead with ML-powered predictions.
Analyze SQL execution patterns across your entire database fleet in a centralized repository.
Deep visibility into Exadata systems including storage, compute, and network performance.
Monitor compute resource utilization patterns across your infrastructure fleet.
Visualize CPU, memory, I/O and storage utilization trends across your database and host fleet.
Predict future resource requirements using machine learning based on historical patterns.
Identify problematic SQL statements and optimization opportunities across your database fleet.
Consolidate AWR data from multiple databases for centralized performance analysis.
Centralized SQL analysis across your entire database fleet - identify problematic queries and optimization opportunities.
| SQL ID | Database | Avg Elapsed (ms) | Executions | CPU Impact |
|---|---|---|---|---|
| 9xkz4wm7c2n3p | PROD_ERP_01 | 4,523 | 12,847 | |
| 7fnh2kp9v4m8q | PROD_CRM_02 | 2,891 | 8,234 | |
| 3bmr6yt1x9k2w | PROD_HR_01 | 1,756 | 24,891 |
Operations Insights can help identify underutilized resources and right-sizing opportunities, potentially saving significant infrastructure costs. Enable it on your production databases to get actionable recommendations.
Monitor and manage your Oracle Database fleet with a unified cloud service. Get Performance Hub diagnostics, automated tuning recommendations, and proactive alerting for your on-premises and cloud databases.
Unified monitoring and management for your Oracle Database fleet
Real-time and historical performance analysis with ASH, AWR, and SQL monitoring in one place.
Single pane of glass view across all your managed databases with health status and alerts.
Get automated SQL tuning recommendations and implement fixes with a single click.
Schedule and monitor database jobs across your fleet with centralized management.
Organize databases into logical groups for easier management and bulk operations.
Get notified about performance issues, space problems, and security concerns before they impact users.
Monitor tablespace usage and get recommendations for optimization and space reclamation.
Manage optimizer statistics gathering and staleness across your database fleet.
Database Management supports Oracle Autonomous Databases, Base DB Systems, Exadata Cloud Service, and on-premises Oracle Databases (11g, 12c, 18c, 19c, 21c, 23ai). Connect on-premises databases using Management Gateway or direct registration.
Automated recommendations to optimize SQL performance based on execution analysis.
SQL ID: 7fnh2kp9v4m8q performs full table scan on ORDERS. Creating an index would reduce execution time by ~85%.
↓ 85% Response TimeSQL ID: 3bmr6yt1x9k2w has a suboptimal execution plan. Accepting the SQL Profile would improve cardinality estimates.
↓ 62% CPU UsageTable INVENTORY has stale statistics (last gathered 45 days ago). Fresh statistics would improve optimizer decisions.
↓ 40% Plan ChangesAutomatic Workload Repository for historical performance analysis and diagnostics.
Automatic snapshots every 30 minutes with 8-day retention. Configure custom intervals and retention periods.
Generate HTML/text AWR reports for any time range. Compare periods to identify performance changes.
Active Session History analysis for real-time and historical session activity visualization.
Conversational observability powered by OCI GenAI and MCP
This is a demonstration with pre-built responses showcasing real-world troubleshooting scenarios. The examples below represent actual use cases that can be implemented using OCI GenAI and MCP servers for your observability workflows.
These examples demonstrate how AI-powered observability can accelerate incident resolution across different OCI services.
AI Analysis: Detected 3 SQL statements consuming 78% of DB time. Top offender: SELECT * FROM ORDERS WHERE status='pending' - missing index on status column. AWR shows buffer cache hit ratio dropped to 67%.
Recommended Actions: Create index on ORDERS(status), increase SGA_TARGET, consider query rewrite with pagination.
AI Analysis: Detected 2,847 failed SSH attempts across 12 hosts. 94% originated from 3 IP ranges (185.x.x.x, 45.x.x.x, 91.x.x.x). Peak activity: 03:00-05:00 UTC. Target: root account (89%), admin (11%).
Recommended Actions: Block identified IP ranges via NSG, enforce key-based auth, consider fail2ban or Cloud Guard responder.
AI Analysis: Trace analysis shows /api/checkout avg response time: 12.4s (SLA: 2s). Root cause: payment-service → external-gateway call timing out. 3rd party API latency increased from 200ms to 8s starting 14:30 UTC.
Recommended Actions: Implement circuit breaker pattern, add timeout with fallback, contact payment provider about degradation.
AI Analysis: Pods in prod/api-deployment restarted 47 times in 2 hours. Cause: OOMKilled (memory limit 512Mi, actual usage peaks at 680Mi). Memory leak pattern detected in heap dumps correlating with connection pool growth.
Recommended Actions: Increase memory limit to 1Gi, investigate connection pool leak in API service, enable HPA for automatic scaling.
AI Analysis: VCN Flow Logs show REJECT for TCP/1521 from subnet-app (10.0.1.0/24) to subnet-db (10.0.2.0/24). Security List sl-app-subnet missing egress rule for DB port. Change made by user@example.com at 09:15 UTC.
Recommended Actions: Add egress rule to sl-app-subnet allowing TCP/1521 to 10.0.2.0/24, or use NSG for more granular control.
AI Analysis: ESS job PYUGEN failed for 3 consecutive runs. Error: "Unable to acquire lock on PAY_PAYROLL_ACTIONS". Concurrent job ARCHIVE_PAYMENTS holding lock for 4+ hours. Data volume increased 340% due to new hire batch.
Recommended Actions: Terminate stuck archive job, increase UCM storage allocation, schedule archive jobs during off-peak, partition payroll tables by period.
AI Analysis: Integration SYNC_ORDERS_TO_ERP failed 156 times today. 89% timeout on REST invoke to on-prem endpoint. Network latency to FastConnect increased from 15ms to 890ms. BGP route flapping detected on customer edge router.
Recommended Actions: Check FastConnect partner status, increase OIC connection timeout to 120s, implement async pattern with callback for large payloads.
AI Analysis: Anomaly detected: User APP_SERVICE exported 2.3M rows from CUSTOMERS table at 02:14 UTC (normal: <1000 rows/day). Same user accessed 47 tables in HR schema they never accessed before. Login from new IP: 203.x.x.x (geolocation: unexpected country).
Recommended Actions: Immediately revoke APP_SERVICE credentials, review exported data scope, enable Data Safe SQL Firewall, investigate compromised credentials source.
Connect your AI assistant to live OCI data through secure, standardized protocols.
Query logs, run ML analysis, detect anomalies
logan_execute_query
logan_detect_anomalies
AWR reports, SQL tuning, performance analysis
get_awr_report
analyze_sql
Cloud Guard problems, vulnerability scans
list_problems
get_security_score
Compute, networking, observability metrics
list_instances
get_metrics